
<li><strong>二分搜索树</strong></li>
二分搜索树可以认为是在链表的基础上进一步进行扩展——它支持快速搜索和插入。
二分搜索树基于一个事实:任何一个结点,其左孩子的值小于其值,其右孩子的值大于其值。
private: int n, *v, vn; struct node{ int val; node *left, *right; node(int i) {val = i; left = right = 0; } }; node * root;
初始化时将根设为空,并通过调用递归函数执行其他操作:
IntSetBST(int maxelements, int maxval) { root = 0; n = 0; }
void insert(int t) { root = rinsert(root, t); }
void report(int *x) { v = x; vn = 0; traverse(root); }
rinsert函数的作用是遍历查值以及插值:
node * rinsert(p, t) if p == 0 //子树为空 p = new node(t) n++ else if t < p->val p->left = rinsert(p->left, t) else if t > p->val p->right = rinsert(p->right, t) return p
traverse函数的作用则是中序遍历:
void traverse(p) if p == 0 return traverse(p->left) v[vn++] = p->val traverse(p->right)
<li><strong>用于整数的结构</strong></li>
这一小节介绍的是充分利用整数特性的结构,使得这些结构有一些特殊的优势。
首先是在第一章就已经亮相的位向量。其私有数据和函数为:
enum { BITSPERWORD = 32, SHIFT = 5, MASK = 0x1f };
int n, hi, *x;
void set(int i) { x[i >> SHIFT] |= (1<<(i & MASK)); }
void clr(int i) { x[i >> SHIFT] &= ~(1<<(i & MASK)); }
int test(int i) { return x[i >> SHIFT] & (1<<(i & MASK));}
构造函数为数组分配空间,将所有位置为0:
IntSetBitVec(maxelements, maxval) hi = maxval x = new int[1 + hi/BITSPERWORD] for i = [0, hi] clr(i) n = 0 void report(v) j = 0 for i = [0, hi] if test(i) v[j++] = i void insert(t) if test(t) return set(t) n++
最后一个数据结构结合了链表和位向量的优点,它在箱序列中放入整数。如果有0-99范围内4个整数,就将其放入4个箱中:箱0包含0-24,箱1包含25-49范围整数,以此类推。比如(原书中第一个箱中的数字是26而非23,我认为这是一个“绘图错误”,所以我重新绘制了下面的图——或许,难道是我打开的方式不对?):
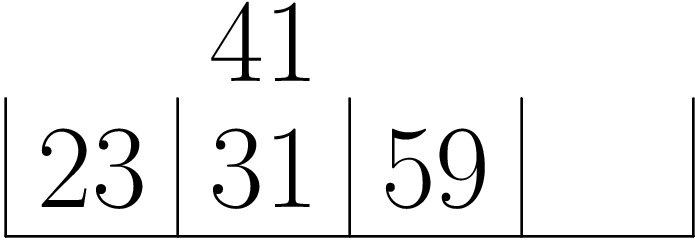
这m个箱可以看作一种散列,每个箱中的整数用一个有序链表表示,由于整数是均匀分布的,所以每个链表的期望长度是1。
箱的私有数据为:
private:
int n, bins, maxval;
struct node{
int val;
node *next;
node(int v, node *p) { val = v; next = p; }
};
node **bin, *sentinel;
构造函数为箱数组和哨兵元素分配空间,并为哨兵赋一个比较大的值:
IntSetBins(maxelements, pmaxval) bins = maxelements maxval = pmaxval bin = new node*[bins] sentinel = new node(maxval, 0) for i = [0, bins) bin[i] = sentinel n = 0
insert函数需要将整数t放入合适的箱中,直观的映射t*bins/maxval可能导致数值溢出,因此我们采用下述代码所示的更安全的映射:
void insert(t) i = t / (1 + maxval/bins) bin[i] = rinsert(bin[i], t)
此处的rinsert类似于前面用于链表的rinsert。类似地,report函数本质上也是把对应的链表代码按顺序应用到了每个箱上:
void report(v) j = 0 for i = [0, bins) for (node * p = bin[i]; p != sentinel; p = p->next) v[j++] = p->val
下表给出了几种结构在作者机器上的运行时间。最大整数规模n=108。m可以尽可能增大,直到系统内存装不下为止。
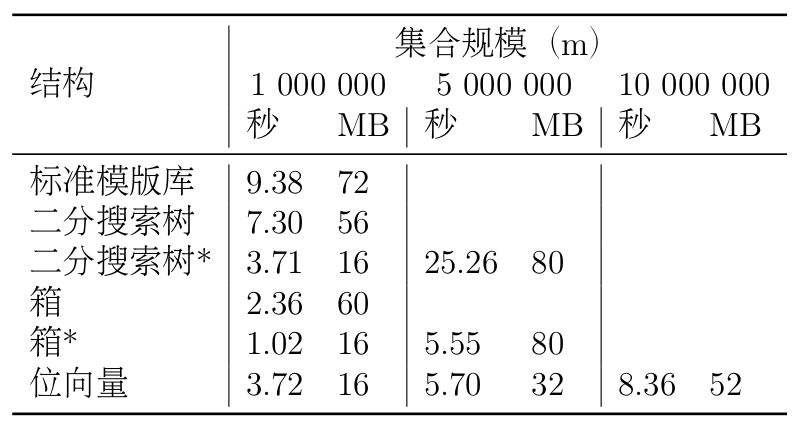
标记为“二分搜索树*”的一行描述了进行几种优化后的二分搜索树运行情况。最重要的是它一次性地为所有结点分配空间,这大大降低了树的空间需求,从而大约能使运行时间降低三分之一。该代码还将递归转化为迭代,并使用了哨兵结点,这又使速度提高了25%。
标记为“箱*”的一行描述了做出在初始化阶段为所有结点分配空间的修改后箱的运行时间,修改后的代码大约只需要原先四分之一的空间和一半的时间。消除递归可以进一步缩短10%运行时间。
<li><strong>原理总结</strong></li>
本章介绍了5种表示集合的重要数据结构。若m相对于n比较小,这些结构的平均性能如下表所示。
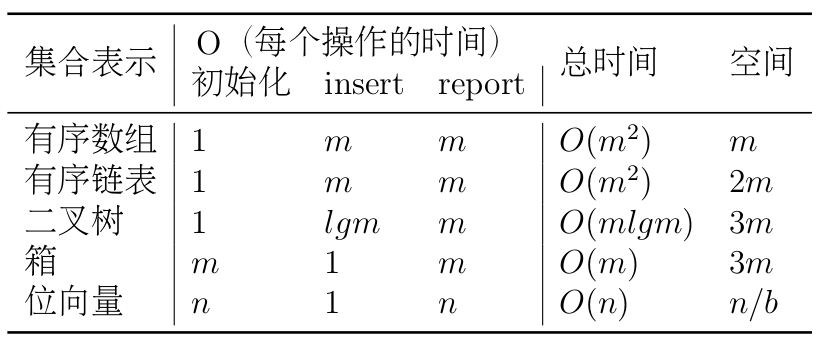
库的作用。 C++标准模版库提供了一种实现容易,而且维护和扩展也比较简单和通用的解决方案。当遇到涉及到数据结构的问题时,我们的第一反应应该是寻求解决问题的通用工具。但在本章例子中,专用的代码可以充分利用特定问题的性质,大大提高运行速度。
空间的重要性。 在线性结构小节中,我们看到调优得很好的链表虽然完成的工作只有数组的一半,但却需要两倍于数组的时间。因为数组中每个元素所占的内存只有链表的一半,而且数组是顺序访问内存的。在二分搜索树一节,可以看到使用定制的内存分配方案可以使空间降为原来的三分之一,时间降为原来的一半。当所需的内存超过0.5MB(作者计算机的二级缓存的大小)并且接近空闲内存大小时,运行时间显著增加。
代码调优方法。 最显著的改进就是用只分配一个较大内存块的方案来替换通用内存分配。这样就消除了很多开销很大的调用,而且也使空间的利用更加有效。将递归函数重写为迭代版本可以使链表的速度提升为原来的3倍,但只能使箱提速10%。对大多数结构来说,引入哨兵可以获得清晰、简单的代码,并缩短运行时间。
<li><strong>习题部分</strong></li>
(习题7)我们的数组、链表和箱都使用了哨兵。说明如何将哨兵用于二分搜索树。
把以前的null指针都指向哨兵结点,哨兵在构造函数中进行初始化:
root = sentinel = new node
插入代码先将目标t放入哨兵结点,然后自顶向下遍历树直至找到t,依次判断t是否在集合中。
void insert(t) sentinel->val = t p = &root while (*p)->val != t if t < (*p)->val p = &((*p)->left) else p = &((*p)->right) if *p == sentinel *p = freenode++ (*p)->val = t (*p)->left = (*p)->right = sentinel n ++
其中结点变量声明并初始化如下:
node **p = &root
freenode是一次性分配内存方案中指向下一个空闲位置的指针。
(习题9)说明如何通过使用低开销的逻辑移位代替高开销的除法运算来对箱进行加速。
可以通过下面的方法简化除法运算。首先对变量进行初始化:
goal = n/m binshift = 1 for (i = 2; i < goal; i *= 2) binshift ++ nbins = 1 + (n >> binshift)
插入函数从该结点开始:
<
pre style='color:#000000;background:#ffffff;'>
p = &(bin[t >> binshift])