
本章讨论的是搜索问题中的数据结构。作者依次描述了适用于不同情境下的数据结构,存储的数据信息均为整数。
要实现的伪代码:
initialize set S to empty size = 0 while size < m do t = bigrand() % maxval if t is not in S insert t into S size ++ print the elements of S in sorted order
(数据结构)接口的定义:
class IntSetImp { public: IntSetImp (int maxelements, int maxval); //将集合初始化为空 void insert (int t); //插入新整数t int size(); //返回集合中的元素个数 void report(int *v); //将元素写入到向量v中 };
使用上述结构生成随机整数有序集合的例子:
void gensets(int m, int maxval){ int * v = new int[m]; IntSetImp S(m, maxval); while (S.size() < m) S.insert(bigrand() % maxval); S.report(v); for (int i = 0; i < m; i++) cout << v[i] << “\n”; }
采用C++ set模版实现的最简单的上述数据结构:
class IntSetSTL{ private: set<int> S; public: IntSetSTL(int maxelements, int maxval) { } int size() { return S.size(); } void insert(int t) { S.insert(t); } void report(int *v){ int j = 0; set<int>::iterator i; for (i = S.begin(); i != S.end(); i++) v[j++] = *i; } };
<li><strong>线性结构</strong></li>
本小节用两种不同的数据结构实现上述集合结构——整数数组和链表。
整数数组实现集合:
private: int n, *x; //元素个数n,x指向整数数组
初始化伪代码:
IntSetArray(maxelements, maxval) x = new int[1 + maxelements] //多分配一个空间用作哨兵 n = 0 x[0] = maxval
插入函数伪代码:
void insert(t) for (i = 0; x[i] < t; i++) ; if x[i] == t return for (j = n; j >= i; j--) x[j+1] = x[j] x[i] = t n++
size函数:
int size() return n
report函数:
void report(v) for i = [0, n] v[i] = x[i]
如果事先知道集合的大小,那么数组是一种比较理想的结构。因为数组是有序的,我们可以用二分搜索建立一个运行时间为O(lg n)的成员函数。
如果事先不知道集合的大小,链表将是表示集合的首选结构,而且链表还能省去插入时元素移动的开销。
用链表实现的IntSetList类私有数据:
private:
int n
struct node{
int val;
node * next;
node(int v, node *p) {val = v; next = p;}
};
node *head, *sentinel;
构造函数:
IntSetList (maxelements, maxval) sentinel = head = new node(maxval, 0) n = 0
report函数:
void report(int *v) j = 0 for (p = head; p != sentinel; p = p->next) v[j++] = p->val
为了使代码简单(消除是否插入在头结点的条件判断),采用递归函数来完成插入操作。
void insert(t) head = rinsert(head, t)
rinsert是一个返回指针的递归函数:
node * rinsert(p, t) if p->val < t p->next = rinsert(p->next, t) else if p->val > t p = new node(t, p) n++ return p
当然,也可以用消除递归的方法来改写上述函数,这样得到的迭代代码将有更快的运行速度。
第一种改写的方法是首先判断是否是在头结点处进行插入,然后分不同的情况分别进行插入操作。
void insert(t) if head->val == t return if head->val > t head = new node(t, head) n++ return for (p = head; p->next->val < t; p = p->next) ; if p->next->val == t return p->next = new node(t, p->next) n++
将上面代码简化,使用指向指针的指针来去除重复:
void insert(t) for ( p = &head; (*p)->val < t; p = &((*p)->next) ) ; if (*p)->val == t return *p = new node(t, *p) n++
这段简化的代码与上述未经简化的代码运行速度一样快。
对于两种线性结构来说,生成m个随机整数时,每次搜索,平均运行时间都与m成正比。因此这两种数据结构的总运行时间都正比于m2。实际上的运行时间如下表所示:
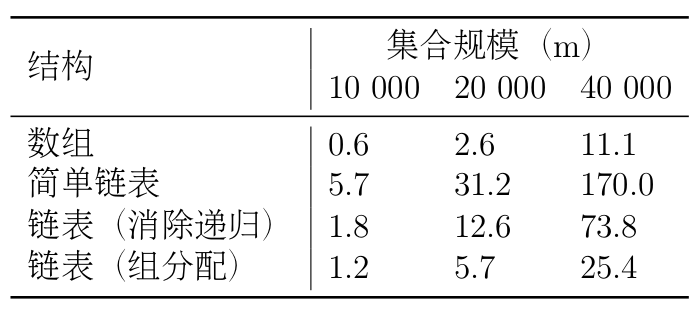
可以看到,简单链表(递归插入方法)的运行速度最慢,它的增长速度明显高于数组方法。这可能是由于递归调用带来的额外开销,通过消除递归,运行时间降低为原来的三分之一左右。
除了递归,另一个可能造成链表运行缓慢的因素是存储分配的方式。书中附录的时间和空间开销模型显示,存储分配的时间开销比大多数简单运算的时间高出两个数量级;将多个结点一次分配为紧凑的数据块消耗的空间要大大少于每次只分配一个结点的方法,这样使得40000个结点消耗的空间大概可以装载于二级缓存中,无疑会带来较大的速度提升。
但作者也提到,在另一个具有更高效分配器的系统中,消除递归带来的加速系数由3变为5,而分配方式带来的加速却只有10%。也就是说,高速缓存和消除递归有时候会带来极大好处,有时却又没什么作用。
与数组插入算法相比,链表插入算法只需要找到插入的位置,而并不需要依次移动后面的元素。但是链表反而需要两倍的时间。主要原因有二:一是它需要两倍的内存,大链表必须要将8字节的结点读入高速缓存以访问4字节的整数;二是数组访问数据时有较好的空间局部性,而链表访问模式可能导致在内存空间的来回跳跃。